CVPR 2020:IR-Net,信息保留的二值神经网络
CVPR 2020:IR-Net,信息保留的二值神经网络在CVPR 2020上,商汤研究院链接与编译组和北京航空航天大学刘祥龙老师团队提出了一种旨在优化前后向传播中信息流的实用、高
在CVPR 2020上,商汤研究院链接与编译组和北京航空航天大学刘祥龙老师团队提出了一种旨在优化前后向传播中信息流的实用、高效的网络二值化新算法IR-Net。不同于以往二值神经网络大多关注量化误差方面,本文首次从统一信息的角度研究了二值网络的前向和后向传播过程,为网络二值化机制的研究提供了全新的视角。同时,该工作首次在ARM设备上进行了先进二值化算法效率验证,显示了IR-Net部署时的优异性能和极高的实用性,有助于解决工业界关注的神经网络二值化落地的核心问题。
动 机
二值神经网络因其存储量小、推理效率高而受到社会的广泛关注 [1]。然而与全精度的对应方法相比,现有的量化方法的精度仍然存在显著的下降。
对神经网络的研究表明,网络的多样性是模型达到高性能的关键[2],保持这种多样性的关键是:(1) 网络在前向传播过程中能够携带足够的信息;(2) 反向传播过程中,精确的梯度为网络优化提供了正确的信息。二值神经网络的性能下降主要是由二值化的有限表示能力和离散性造成的,这导致了前向和反向传播的严重信息损失,模型的多样性急剧下降。同时,在二值神经网络的训练过程中,离散二值化往往导致梯度不准确和优化方向错误。如何解决以上问题,得到更高精度的二值神经网络?这一问题被研究者们广泛关注,本文的动机在于:通过信息保留的思路,设计更高性能的二值神经网络。
基于以上动机,本文首次从信息流的角度研究了网络二值化,提出了一种新的信息保持网络(IR-Net):(1)在前向传播中引入了一种称为Libra参数二值化(Libra-PB)的平衡标准化量化方法,最大化量化参数的信息熵和最小化量化误差;(2) 在反向传播中采用误差衰减估计器(EDE)来计算梯度,保证训练开始时的充分更新和训练结束时的精确梯度。
IR-Net提供了一个全新的角度来理解二值神经网络是如何运行的,并且具有很好的通用性,可以在标准的网络训练流程中进行优化。作者使用CIFAR-10和ImageNet数据集上的图像分类任务来评估提出的IR-Net,同时借助开源二值化推理库daBNN进行了部署效率验证。
方法设计
高精度二值神经网络训练的瓶颈主要在于训练过程中严重的信息损失。前向sign函数和后向梯度逼近所造成的信息损失严重影响了二值神经网络的精度。为了解决以上问题,本文提出了一种新的信息保持网络(IR-Net)模型,它保留了训练过程中的信息,实现了二值化模型的高精度。

前向传播中的Libra Parameter Binarization(Libra-PB)
在此之前,绝大多数网络二值化方法试图减小二值化操作的量化误差。然而,仅通过最小化量化误差来获得一个良好的二值网络是不够的。因此,Libra-PB设计的关键在于:使用信息熵指标,最大化二值网络前向传播过程中的信息流。
根据信息熵的定义,在二值网络中,二值参数Qx(x)的熵可以通过以下公式计算:
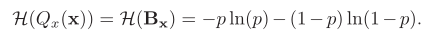
如果单纯地追求量化误差最小化,在极端情况下,量化参数的信息熵甚至可以接近于零。因此,Libra-PB将量化值的量化误差和二值参数的信息熵同时作为优化目标,定义为:
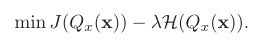
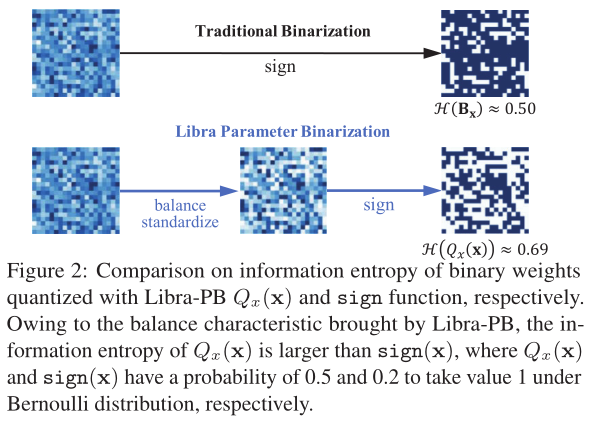
在伯努利分布假设下,当p=0.5时,量化值的信息熵取最大值。
因此,在Libra-PB通过标准化和平衡操作获得标准化平衡权重,如图2所示,在Bernoulli分布下,由Libra-PB量化的参数具有最大的信息熵。有趣的是,对权重的简单变换也可以极大改善前向过程中激活的信息流。因为此时,各层的二值激活值信息熵同样可以最大化,这意味着特征图中信息可以被保留。
在以往的二值化方法中,为了使量化误差减小,几乎所有方法都会引入浮点尺度因子来从数值上逼近原始参数,这无疑将高昂的浮点运算引入其中。在Libra-PB中,为了进一步减小量化误差,同时避免以往二值化方法中代价高昂的浮点运算,Libra-PB引入了整数移位标量s,扩展了二值权重的表示能力。
因此最终,针对正向传播的Libra参数二值化可以表示如下:
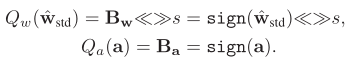
IR-Net的主要运算操作可以表示为:
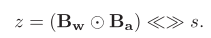
反向传播中的Error Decay Estimator(EDE)
由于二值化的不连续性,梯度的近似对于反向传播是不可避免的,这种对sign函数的近似带来了两种梯度的信息损失,包括截断范围外参数更新能力下降造成的信息损失,和截断范围内近似误差造成的信息损失。为了更好的保留反向传播中由损失函数导出的信息,平衡各训练阶段对于梯度的要求,EDE引入了一种渐进的两阶段近似梯度方法。
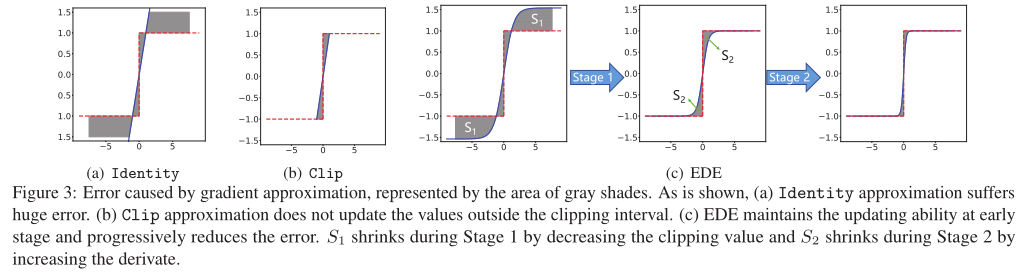
第一阶段:保留反向传播算法的更新能力。将梯度估计函数的导数值保持在接近1的水平,然后逐步将截断值从一个大的数字降到1。利用这一规则,近似函数从接近Identity函数演化到Clip函数,从而保证了训练早期的更新能力。
第二阶段:使0附近的参数被更准确地更新。将截断保持为1,并逐渐将导数曲线演变到阶梯函数的形状。利用这一规则,近似函数从Clip函数演变到sign函数,从而保证了前向和反向传播的一致性。
各阶段EDE的形状变化如图3(c)所示。通过该设计,EDE减小了前向二值化函数和后向近似函数之间的差异,同时所有参数都能得到合理的更新。
实验结果
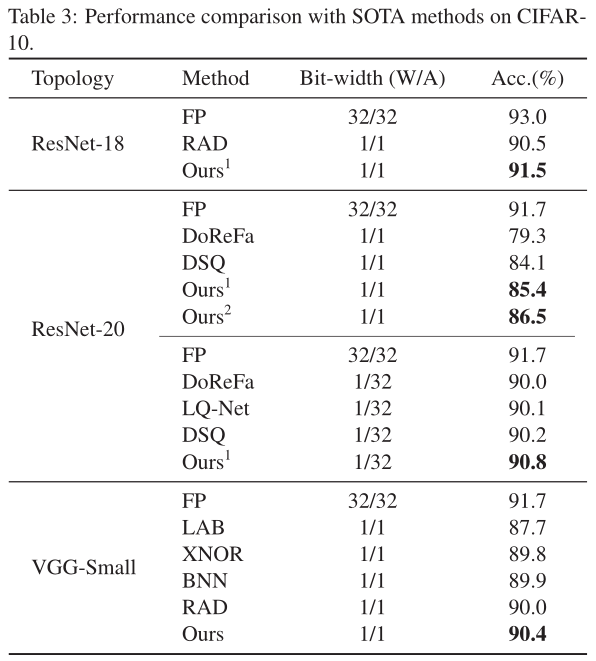
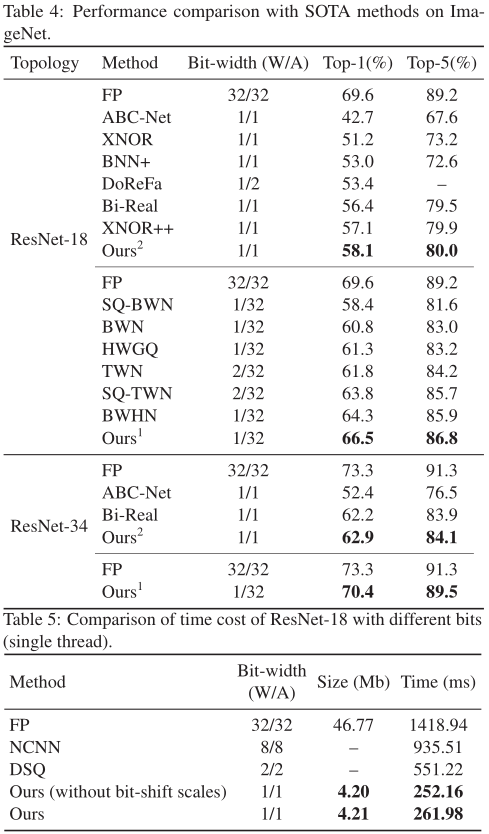
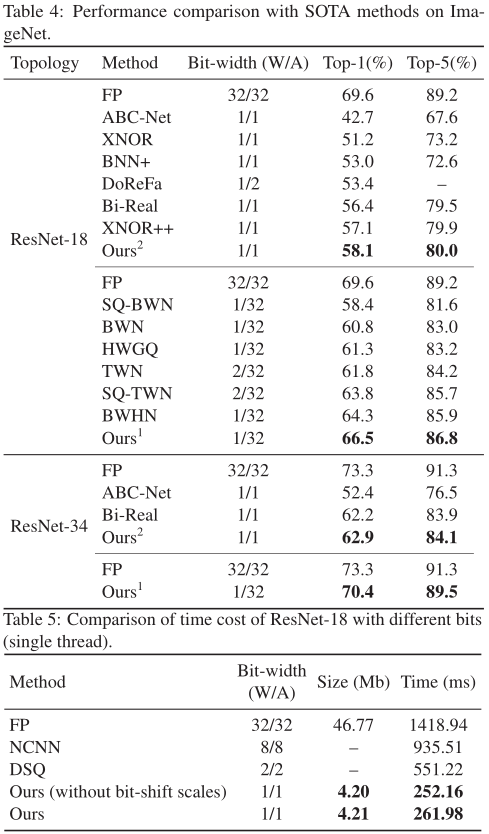
作者使用了两个基准数据集:CIFAR-10和ImageNet(ILSVRC12)进行了实验。在两个数据集上的实验结果表明,IR-Net比现有的最先进方法更具竞争力。
Deployment Efficiency
为了进一步验证IR-Net在实际移动设备中的部署效率,作者在1.2GHz 64位四核ARM Cortex-A53的Raspberry Pi 3B上进一步实现了IR-Net,并在实际应用中测试了其真实速度。表5显示,IR-Net的推理速度要快得多,模型尺寸也大大减小,而且IR-Net中的位移操作几乎不会带来额外的推理时间和存储消耗。
Reference[1] Rastegari M, Ordonez V,Redmon J, et al. Xnor-net: Imagenet classification using binary convolutionalneural networks[C]//ECCV. Springer, Cham, 2016: 525-542.[2] Xie B, Liang Y, Song L.Diverse neural network learns true target functions[J]. arXiv preprintarXiv:1611.03131, 2016.
-
中国电信NB-IoT模组开年“第一标”:芯翼信息科技如何摘得桂冠?2020-04-15
-
康奈尔大学研究员提出利用归一化信息, 提取图像特征中结构性信息的新方法2020-04-09
-
医院成为信息化抗疫主推手,管理体系智能化转变是大势所趋2020-04-02
-
市场规模约582亿元,医疗信息化中标数据中我们还发现了这些有趣的地方2020-03-30
-
工业和信息化部发布《关于推动5G加快发展的通知》2020-03-30
-
2019医疗信息化中标数据分析,最高中标金额近1.2亿元,三级医院需求占六成2020-03-26
-
工业和信息化部关于推动5G加快发展的通知2020-03-25
-
新一代信息基础设施建设大火,到底建些什么?2020-03-23
-
精研“军力倍增器”,兴图新科如何帮中国打赢信息化战争?2020-03-20
-
新一代信息基础设施建设大火,到底都建些啥呢?2020-03-20
-
领克05限量版发布:指纹识别一触读取个人信息2020-03-20
-
专注消毒追溯软件研发,聚仁医疗利用信息化为院内新冠疫情防控赋能2020-03-11
-
日系车更轻了!本田采用3D打印技术打造轻量化零部件2020-03-09
-
国家工业信息安全发展研究中心发布《自动驾驶数据安全白皮书(2020)》2020-03-05
-
对话 InterSystems :疫情背后,医疗信息化进度条将被加快2020-03-03